

Estrategias Online
Cómo posicionar tu web en Google si eres una pyme

(Especialista SEO)
Durante años, tener éxito en internet significaba básicamente una cosa: convencer a personas.
Que Google entendiese bien tu web, que el usuario encontrase lo que buscaba, que el diseño y los textos fuesen claros para que esa visita terminase en un lead, una llamada o una venta.
Esto sigue siendo fundamental. No ha cambiado y no va a cambiar en el corto plazo.
Lo que sí ha cambiado es que las personas ya no son las únicas que acceden a tu página web para obtener información. Cada vez que alguien le pide a ChatGPT, Claude o Perplexity que busque un servicio o compare productos, estos modelos acceden a webs, leen su contenido y deciden qué información es relevante para darte respuesta. Y esto es solo la primera capa. Hemos entrado en una nueva fase donde existen agentes de IA capaces de navegar webs de forma autónoma: rellenar formularios, comparar productos, hacer reservas. Son pocos y torpes todavía, pero esto es solo el principio.
¿Y cómo tienen que ser las webs para estos "nuevos visitantes"? Pues en este post nos centramos en eso:

Antes de entrar en el turrón, vamos a aclarar un par de conceptos que se mezclan constantemente y que conviene separar.
Cuando le pides a ChatGPT, Claude o Perplexity que busque información, el modelo lanza una búsqueda, accede al contenido de varias páginas web y sintetiza una respuesta con lo que ha encontrado. No te devuelve una lista de enlaces como haría Google. Interpreta la información, la resume y decide qué es relevante para ti. Y para hacer eso bien, necesita entender qué hay en cada página que visita.
Esto ya tiene implicaciones directas para tu web. Si tu contenido no está bien estructurado, si tu información clave está enterrada entre capas de HTML poco útil o si tus metadatos no dicen claramente qué ofreces, estos modelos van a tener problemas para entenderte. Y si no te entienden, no te recomiendan.
Pero hay un segundo nivel.
Un agente de IA va un paso más allá: no solo lee, también actúa. Es un programa capaz de navegar por una web de forma autónoma, interactuar con la interfaz, rellenar formularios, hacer clic en botones, comparar opciones entre varias páginas y tomar decisiones sin que un humano le diga exactamente dónde pulsar.
Herramientas como Operator de OpenAI, las capacidades de computer use de Claude o los browser agents que están integrando navegadores como Chrome ya funcionan de esta manera. No son ciencia ficción que vendrá en unos años, aunque tampoco son el día a día de la mayoría de usuarios. Todavía.
Lo importante es entender que las dos cosas (modelos que leen webs y agentes que interactúan con ellas) forman parte del mismo movimiento. Y la web necesita adaptarse a ambos.
Toda la web que conocemos fue diseñada para ojos humanos. Los colores, los márgenes, las animaciones, la disposición de los bloques... todo está pensado para que una persona mire una pantalla y entienda qué tiene delante.
Una máquina no ve nada de eso.
Cuando un modelo de IA o un agente accede a tu web, se encuentra con el código fuente. Y ahí las cosas se ponen feas.
Imagina que para saber el horario de un restaurante tuvieras que leer el HTML completo de su página: cientos de líneas de divs, clases CSS, scripts de analytics, banners de cookies, menús de navegación... y en algún punto del camino, el dato que buscas. Pues eso es lo que hace un modelo cuando accede a tu web para extraer información.
Y cuando hablamos de agentes autónomos que necesitan interactuar con la interfaz, la cosa es todavía peor. Los dos métodos que dominan hoy son los siguientes:
El primero son las capturas de pantalla. El agente toma una imagen de la web y la envía a un modelo multimodal para que interprete visualmente dónde está cada elemento. Cada imagen consume miles de tokens de procesamiento. Es lento y caro.
El segundo es el parseo del DOM. El agente ingiere el HTML completo de la página y busca información relevante entre todo el ruido. También lento, también caro, también frágil porque cualquier cambio en el diseño puede romper el proceso.
En ambos casos, hay una traducción forzada entre lo que la web fue diseñada para hacer (ser vista por ojos humanos) y lo que la máquina necesita (datos estructurados sobre el contenido y las acciones disponibles).
Una búsqueda de producto que tú completas en tres segundos puede requerir decenas de peticiones de un agente para conseguir el mismo resultado.
Y aquí es donde entra lo interesante. Porque en las últimas semanas se han movido piezas muy grandes para resolver exactamente este problema.

No estamos hablando de predicciones. Esto ya ha pasado o está pasando en este momento, y tiene implicaciones directas para cualquier proyecto web.
Si hay una pieza que explica hacia dónde va todo esto, es MCP.
El Model Context Protocol nació en noviembre de 2024 como un estándar abierto lanzado por Anthropic (los creadores de Claude). La idea era resolver un problema muy concreto: cada vez que un modelo de IA o un agente necesitaba conectarse con una herramienta o servicio externo, había que construir una integración específica para esa combinación. Si tenías diez modelos y diez servicios, necesitabas cien integraciones diferentes.
MCP propone que todos hablen el mismo idioma. Un único protocolo estándar para que cualquier modelo o agente se conecte con cualquier herramienta. Es como cuando el USB-C sustituyó al caos de cables diferentes: un solo conector para todo.
En doce meses pasó de experimento interno a estándar de facto de la industria:
En marzo de 2025, OpenAI lo adoptó para ChatGPT. En abril, Google DeepMind confirmó soporte para Gemini. En mayo, Microsoft anunció su integración en Windows 11. Y en diciembre de 2025, Anthropic donó MCP a la Linux Foundation, creando la Agentic AI Foundation con OpenAI, Google, Microsoft, AWS y Cloudflare como miembros fundadores.
A día de hoy hay más de 10.000 servidores MCP públicos activos y 97 millones de descargas mensuales de su SDK. Tiene soporte nativo en Claude, ChatGPT, Gemini, Microsoft Copilot, Cursor y VS Code.
Cuando algo deja de ser un proyecto de una empresa y pasa a ser gobernado por la Linux Foundation con los cinco gigantes dentro, ya no es una moda. Es infraestructura.
¿Y qué tiene que ver esto con tu web? Todo. Porque los dos avances que vienen a continuación se apoyan directamente en este ecosistema.
Desde el 12 de febrero de 2026, la red de Cloudflare (que gestiona el tráfico de una parte enorme de internet) puede convertir automáticamente cualquier página HTML a Markdown cuando un modelo o agente lo solicita.
¿Por qué importa esto?
Porque un agente que lee HTML gasta entre cuatro y cinco veces más recursos que uno que lee Markdown. El propio ejemplo que publicaron lo dejó claro: la misma página en HTML ocupaba 16.180 tokens y en Markdown se quedaba en 3.150. Una reducción del 80%.
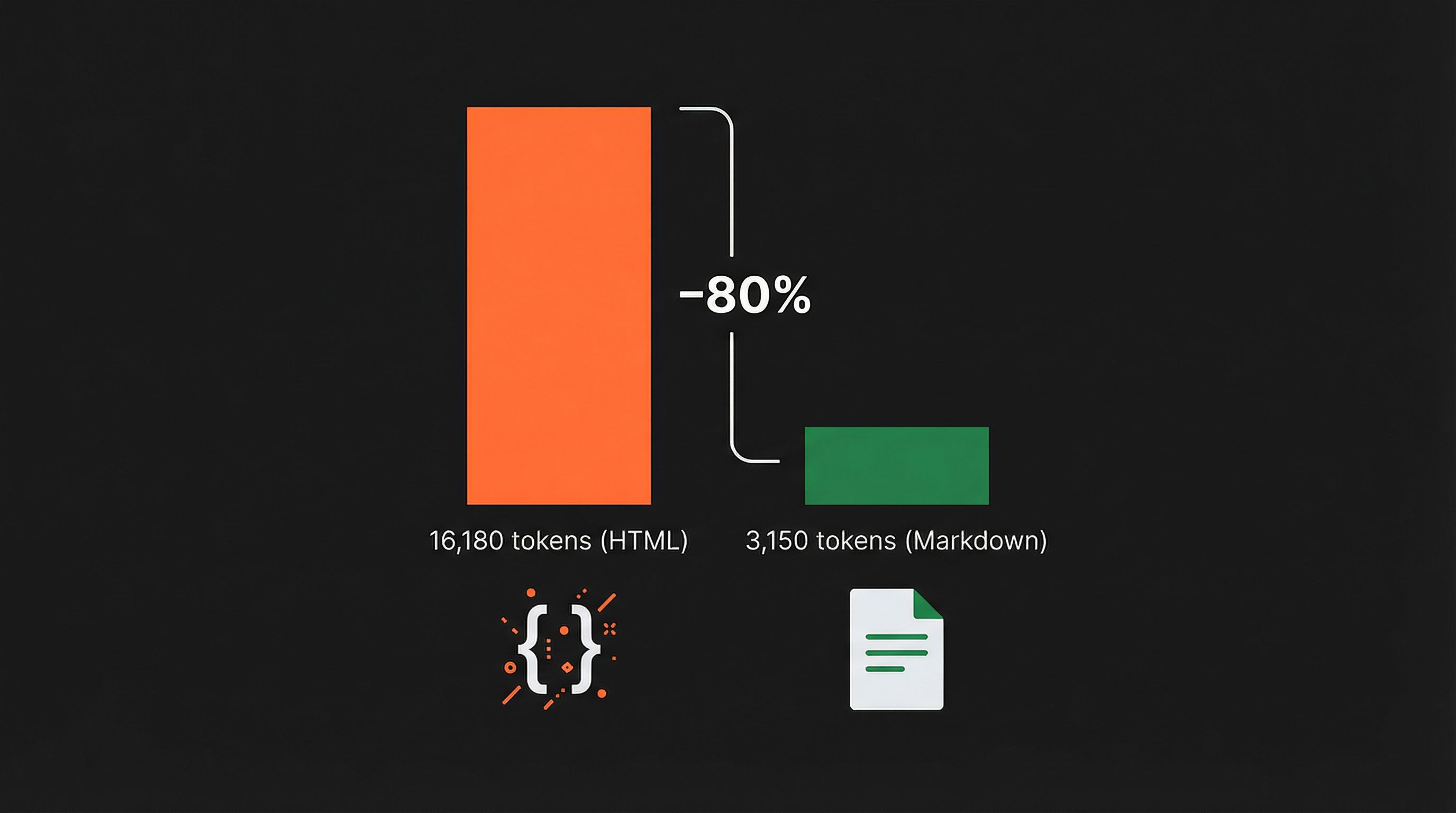 El mecanismo funciona así: el modelo o agente envía una cabecera HTTP pidiendo el contenido en formato Markdown y Cloudflare le devuelve el texto limpio, sin navegación, sin estilos, sin ruido. Solo el contenido que importa.
El mecanismo funciona así: el modelo o agente envía una cabecera HTTP pidiendo el contenido en formato Markdown y Cloudflare le devuelve el texto limpio, sin navegación, sin estilos, sin ruido. Solo el contenido que importa.
Además, incluye un sistema de permisos mediante el header Content-Signal que permite al propietario de la web controlar si su contenido puede usarse para entrenar modelos de IA, para búsquedas o como input de agentes. Tú decides qué pueden hacer con tu contenido.
Si tu web pasa por Cloudflare (y hay bastantes probabilidades de que así sea), activar esto es prácticamente inmediato.
Esto es un movimiento de Google y Microsoft juntos, incubado en un grupo de trabajo del W3C. Se llama WebMCP y es una propuesta de estándar web que permite a cualquier página decirle directamente a un agente qué herramientas tiene disponibles y cómo usarlas.
En lugar de que el agente tenga que hacer ingeniería inversa de tu HTML para descubrir que tienes un buscador, un formulario de contacto o un sistema de reservas, tu web le dice: "aquí tienes un buscador, estos son los campos, así se usa".
Lo interesante es que tiene dos niveles de implementación. El primero es declarativo: se añaden atributos a los formularios HTML que ya tienes. Si tus formularios están limpios y bien estructurados (con labels correctos, campos con nombres semánticos y una estructura limpia), estás prácticamente al 80% de compatibilidad sin tocar nada. El segundo es imperativo, para interacciones más complejas que requieren JavaScript.
Ahora mismo está disponible en Chrome 146 Canary detrás de un flag experimental. Se espera el anuncio formal en Google I/O 2026.
Dicho con otras palabras: tener formularios bien hechos deja de ser solo una cuestión de usabilidad para convertirse en infraestructura de la nueva web.
¿Conoces el fichero robots.txt? Ese archivo que colocas en la raíz de tu web para decirle a los buscadores qué páginas pueden rastrear y cuáles no.
Hay un equivalente emergente para los modelos y agentes de IA: el fichero llms.txt.
La diferencia es de enfoque. Mientras que robots.txt controla el acceso (puedes entrar aquí, no puedes entrar allí), llms.txt facilita la comprensión. Le dice al modelo o agente qué eres, qué ofreces, cuáles son las páginas más importantes de tu web y cómo está organizado tu contenido.
No es un estándar oficial ratificado todavía. La adopción es voluntaria y desigual. Pero lo mismo se podía decir de robots.txt en 1994 o del marcado Schema en 2012. Y ya ves dónde están ahora.
Implementarlo es sencillo, no requiere cambios técnicos complejos y puede darte una ventaja mientras la adopción siga siendo baja. Nosotros estamos ya construyendo el nuestro y el de nuestros clientes. Aquí tienes un ejemplo completo de la gente de Cloudflare.
Todo lo anterior es la capa nueva. Pero existe una capa previa que ya debería estar y que sigue siendo la base sobre la que todo se sostiene. Si esta capa falla, los agentes de IA son el menor de tus problemas.
Esto dejó de ser opcional hace tiempo. Los modelos y agentes usan el marcado Schema para entender el contexto de tu web sin tener que procesar todo el contenido. Es la forma más directa de decirle a una máquina qué eres y qué ofreces. Como mínimo: Organization o LocalBusiness, más los tipos relevantes para tu negocio (Product, Article, FAQPage, BreadcrumbList...). Google tiene herramientas gratuitas para validarlo.
Un H1 claro que diga de qué va la página. Jerarquía de H2 y H3 coherente, sin saltos de nivel. Sin titulares decorativos que no aporten contexto semántico. Las máquinas leen la estructura antes que el contenido. Si tu jerarquía de encabezados no tiene sentido, tu contenido tampoco lo tendrá para ellas.
Title preciso y único por página. Meta description descriptiva. Open Graph configurado para que cuando alguien comparta tu web en redes o un modelo extraiga información, el contexto sea el correcto. Canonical bien puesto para evitar confusión sobre cuál es la versión principal de cada página. Esto no es nuevo pero sigue habiendo webs que lo tienen a medias.
Labels correctos asociados a cada campo. Campos con nombres semánticos (name, email, phone... no field1, field2). Estructura limpia sin capas innecesarias de divs. Si tus formularios cumplen esto, ya estás al 80% de compatibilidad con WebMCP cuando llegue. Y si no lo cumplen, tienes un problema de usabilidad que va más allá de los agentes.
Los agentes también penalizan la lentitud. Una web que carga lento consume más recursos cuando una máquina accede a ella. LCP, CLS e INP siguen siendo relevantes y lo van a seguir siendo.
Esta es la parte que separa a los que se preparan de los que van a ir detrás.
Crear un fichero llms.txt en la raíz del dominio. Estructura la información de tu proyecto de forma que un modelo pueda entender rápidamente qué eres, qué ofreces y cuál es tu contenido más importante. No es complejo de hacer y ahora mismo te pone por delante de la inmensa mayoría de webs.
Activar Markdown for Agents si tu web pasa por Cloudflare. Es un cambio de configuración que permite a los modelos acceder a tu contenido de forma limpia, consumiendo una fracción de los recursos. No hay motivo para no hacerlo.
Auditar tus formularios principales con la mentalidad de WebMCP. No necesitas implementar nada todavía, pero sí asegurarte de que tu estructura HTML está limpia, que los campos tienen nombres semánticos y que un programa podría entender qué hace cada formulario sin necesidad de ver el diseño.
Revisar si tu contenido más importante es legible sin la capa visual. Haz la prueba: coge las tres páginas más importantes de tu web y léelas en código fuente. ¿Puedes encontrar tu propuesta de valor, tus servicios y tu información de contacto sin perderte en el ruido?
Revisar los permisos sobre tu contenido. Con la llegada de herramientas como el Content-Signal de Cloudflare, los propietarios de webs van a poder decidir qué pueden hacer los modelos y agentes con su contenido. Tener una posición clara sobre esto (qué permites, qué no) va a ser cada vez más necesario.
En 2005, apostar por el SEO era una ventaja competitiva. En 2015, era obligatorio. Hoy nadie se plantea si necesita una web optimizada para buscadores.
El mismo patrón se está repitiendo con la optimización para modelos y agentes, pero comprimido en mucho menos tiempo.
Los que empiecen a preparar sus proyectos ahora tienen una ventana de 12 a 18 meses antes de que esto deje de ser ventaja y pase a ser el mínimo exigible.
Tu proyecto no tiene que reinventarse. Tiene que estar preparado.
Y si quieres que revisemos cómo está el tuyo, tienes un formulario justo aquí abajo para que hablemos.
(Especialista SEO)
También te puede gustar
000 THECOOKIES Terminal v1.0
Escribe tu email para iniciar una conversación con nuestro asistente de IA.
────────────────────────────────────────────────────────



